
How Do We Compute xBar & s? What are they???
Section Goals:
Introduction: In chapter 4, we worked many problems with the Gaussian Distribution and they always required us to know the mean μ (average) and standard deviation σ for the population of 'things' we were analysing. Chapter 4 identified three sources of those values:
Computing xΒar (imposter for μ):
Please recall that μ is the average value for every item belonging to the population. If we are talking about the length of large construction nails, then μ is the average of length for every 16d size nail produced from Columbus up through the 22nd century. We would measure and add up all the lengths, and then divide the answer by the number of nails.
If we are talking about the weight of Cows, then μ is the average weight for every cow from the time of Moses up through the 22nd century. We would add up all the weights, then divide by the number of cows. We would need a time machine go back and weigh every cow because Moses lived a very long time ago. For most populations, it simply is not possible to get population data to compute μ. That is the reason we have to work with sample values xBar and σ.
So, how do you find the mean of x? Just add up all the x values, and then divide by their number. If you use 'all of them', then you get μ. If you use a sample of them, you will get xBar.
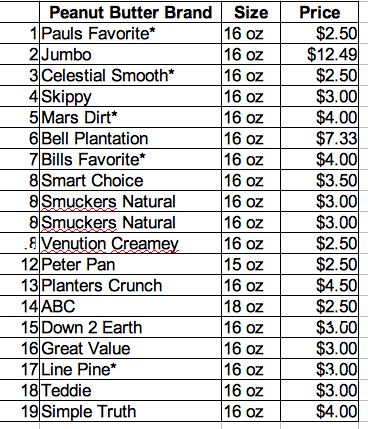
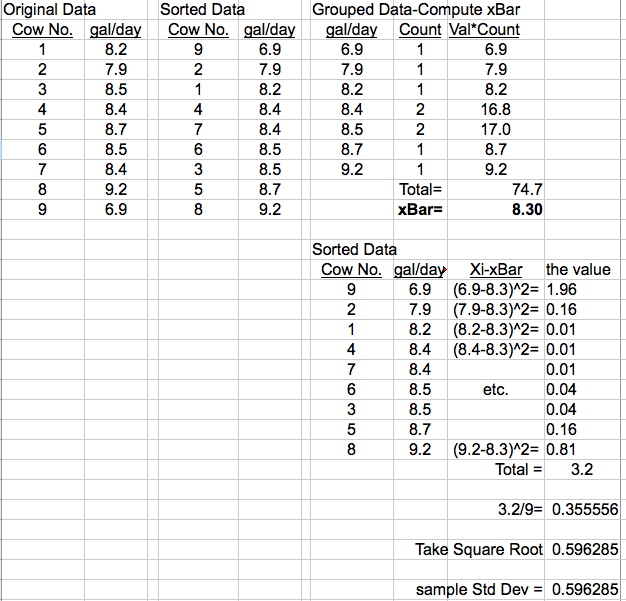
We can compute the sample mean 'xBar' based on the 19 prices in Table 1. Likely, you know the method, but here is the example:
Presenting Data - A Better Way: From Table 1, it is not obvious, but prices range from $1.50 to $12.99 for a jar of peanut butter. It is not obvious, but Table 1 has 6 products priced at $2.50.
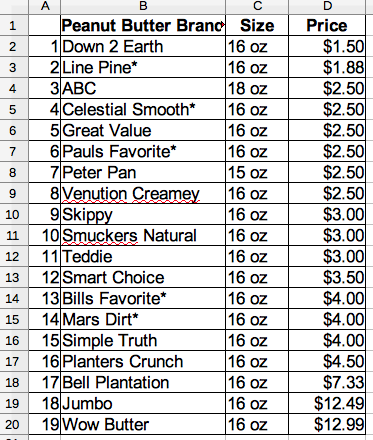
Further simplifications are possible. To compute xBar (the imposter for μ), we don't need the names of the peanut butter and we don't need jar size. Repeat entries are handled as shown in Table 3 below:
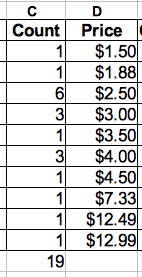
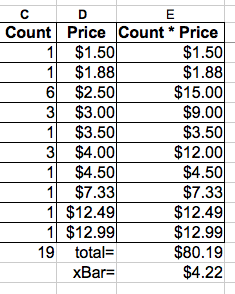
An Easier Way to Compute xBar:
Based on Table 3, we can compute xBar either by calculator or by computer spreadsheet. We simply multiply 'Count' by 'Price' for each row in Table 3. Typically, these values are inserted into a new column to the right. Then, we 'total down' the new column. Finally, divide by the total by count of data items (19 in this example). Confused? We are just adding up all the Price numbers of Table 2 in a smarter way!
For a table with 19 data entries, it is not very important how you do it. But in the real world, statistics problems often have 150 data rows. For situations like this, it is impossible to look at the data table and draw any kind of conclusion. The data table must be sorted and repeat entries should be documented in a 'Count' column (like Table 3). This approach also makes computation of xBar much faster.
Reduced to math notation, this 'easier way' to compute sample mean looks like this:
Homework Problems Chapter 5 :
For problems 1 through 4, use the data set to do the following. You may use either calculator or computer spreadsheet. Show all work.
Chapter 5 Problem 1:
A Washington 'think tank' is encouraging larger budgets for health research. They want to statistically describe U.S. child deaths from Flu. Data from National Institute of Health follows
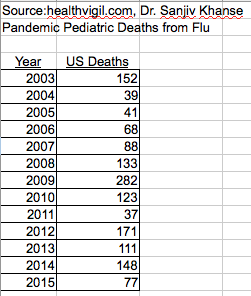
Banded Data: Very often, data is tabulated as huge lists of items with one entry per row. For example: Paul bought a pair of size 9 shoes → that appears as one data row. Tommy bought a pair of size 9 shoes → that is a different data row. When data items arrive as separate line items, but clearly many of the entries are similar, it makes sense to sort the data, and then group all the size 9 purchases together. It is very common to arrange data into 'bands' that fall into certain value ranges. For shoes, it seems very natural; but 'banded' data is quite common even when the 'x' variable seems continuous and repeats in the data are not evident. We will explore this topic when we study histograms in Chapter 6.
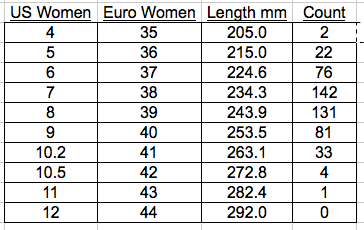
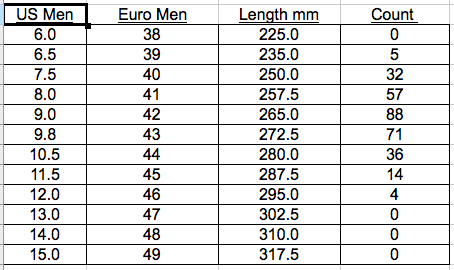
For problems 3 and 4, the data has already been sorted and grouped for you. Ignore the columns of data you don't need. Compute the mean of the data set.
Chapter 5 Problem 3:
Shoe manufacturers are very interested in knowing the percentage of each shoe size sold so they can manufacture shoes in the proportions demanded by the market. Below, is a sorted data set that shows a sample of women's shoe purchases. Find the average.
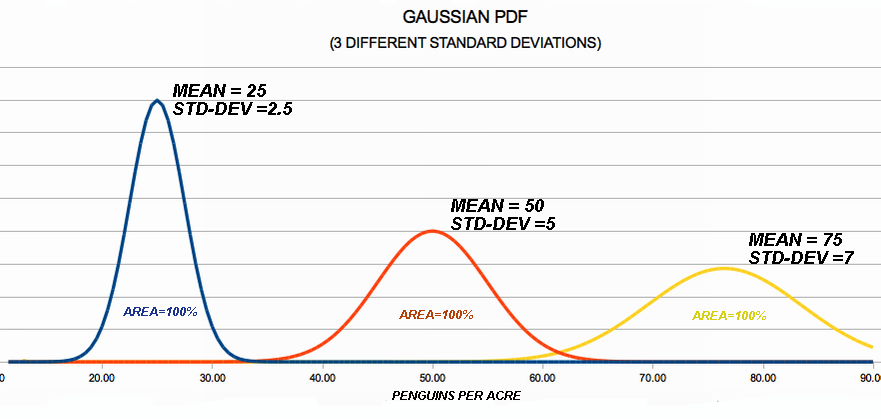
How is the Mean μ Related to the PDF? I offer a few PDF pictures with the mean shown on the graph. The mean of the PDF graph is always the balancing point! These four images illustrate that idea.
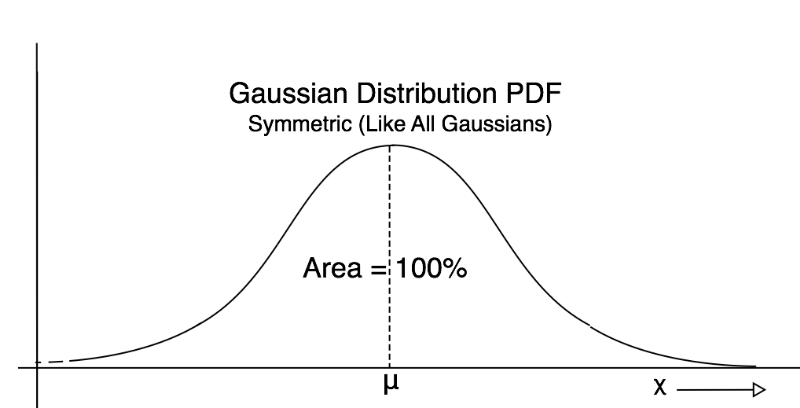
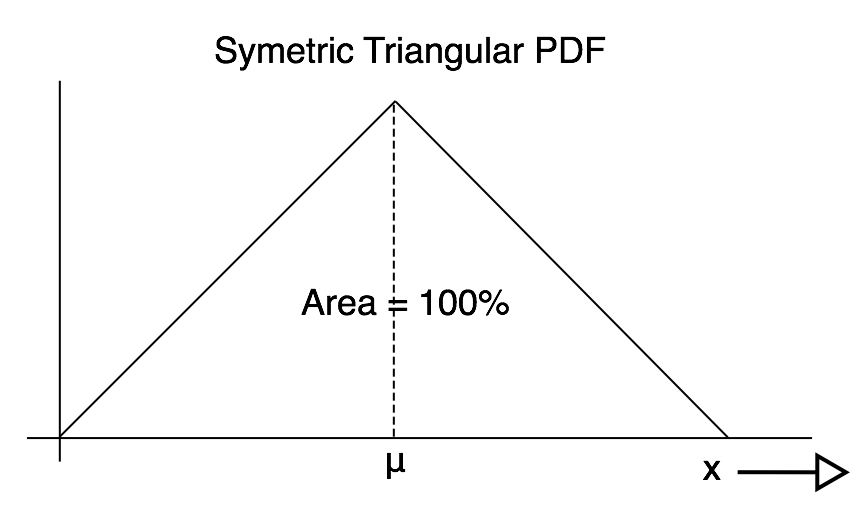
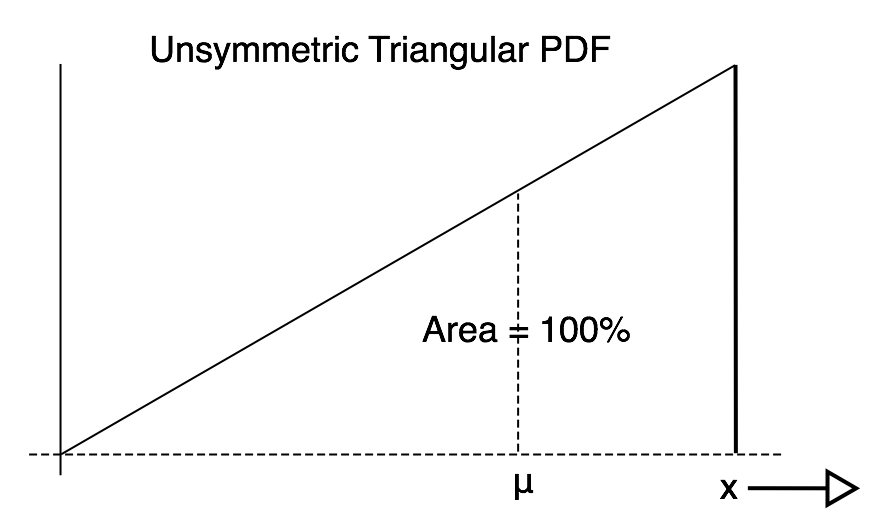
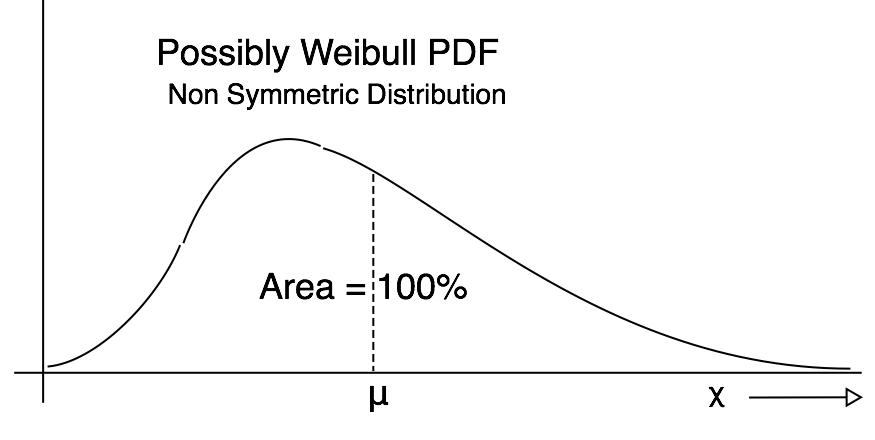
Mid Chapter Summary:
The Variance σ and imposter s:
We know from Chapter 2 that the standard deviation σ determines 'how wide' the Gaussian PDF is. Chapter 2 Figure 3 is repeated below to refresh your memory. From the figure below, you should get the idea that:
Computing s (imposter for standard deviation σ): In the real world, you usually won't know the standard deviation σ. You will have to compute an estimate based on a sample of data. A sample based variance is usually denoted 's' which is a way of reminding us that it is not the true, population value σ. s is an imposter that pretends to be the variance σ and we can use it in calculations in place of σ. In mathematical notation, the following equation defines how the sample variance s is computed:
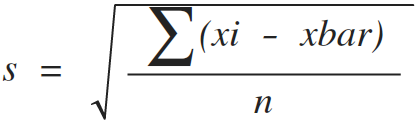
Homework Set 2 Problems Chapter 5:
Problems 5, 6, 7, & 8: Computation of Sample Standard Deviation s:
For each of the data sets of Problems 1,2,3 & 4, Compute the sample mean and sample standard deviation using the method shown above. You may use either calculator and paper, or spreadsheet.
Turn in the results to your instructor.
Contact the author paul-watson@sbcglobal.net
by e-mail.
© 2020 All Rights Reserved
Paul F. Watson
Beginning
of St. Paul's Statistics Introduction
Dionysus.biz Home Page